图形学中经常会涉及到拉普拉斯算子,在这里介绍一下拉普拉斯算子在三角mesh上的具体实现。
预备内容
在真正开始讨论拉普拉斯算子之前,我们先说明一些预备的知识。
局部平均区域
基本思想是将计算微分性质作为mesh上点局部邻域上的空间平均。下图是几种具体情况:
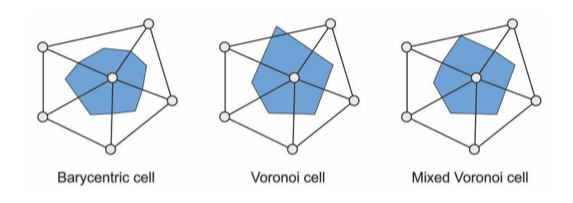
图中的蓝色区域为局部平均区域。其中barycentric cell是将三角形的重心和三角形边的中点相连,Voronoi cell是将重心换成了外心。使用外心有一个问题,对于钝角三角形来说外心在三角形外部,因此mixed Voronoi cell将钝角三角形的外心替换为钝角对边的中点。
梯度
由于拉普拉斯算子是梯度的散度,所以梯度也是很重要的。假设一个由每个mesh顶点定义的逐块线性函数,,内插得到每一个三角形:
其中是在2D共形参数化上的对应参数。内插效果为:
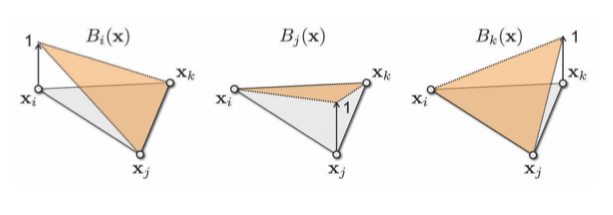
那么的梯度为
由于是线性插值,我们有条件对于所有的我们有,因此。联合上面的式子我们可以得到:
这个函数的最速上升方向是垂直于顶点对边的方向,再加上合适的归一化,有
其中表示逆时针旋转90度,表示三角形的面积。那么在三角形中每一点的梯度为常数:
离散拉普拉斯算子
预备内容说完了开始讲讲主题了
均匀拉普拉斯
拉普拉斯算子的均匀离散版本
总的来说,这个形式用处不大。但是也可以用在各向同性的remesh上。
余切公式
使用混合的有限元/有限体方法(mixed finite element/finite volume method),拉普拉斯算子可以有更精确的离散推导。目标是在局部平均域上,对逐片线性函数梯度的散度进行积分。为了简化这个积分,对向量值函数的积分应用散度定理:
这个等式将面积上的积分转换为了在边界上的积分,其中是边界向外的单位法线。
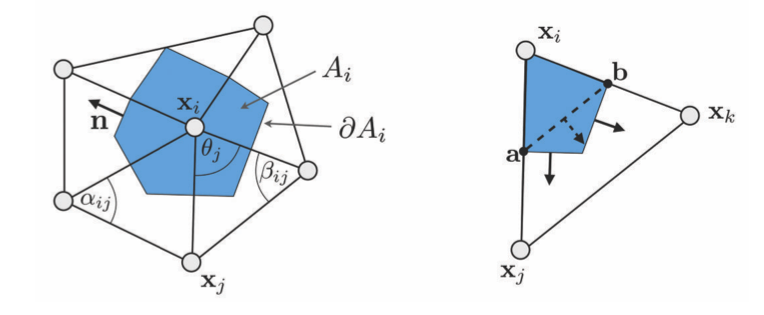
将拉普拉斯应用到散度定理中
将积分分解到每个三角形上。由于局部的Voronoi区域通过三角形两条边的中点和,并且每个三角形中是常数,那么在该三角形上的积分为
然后我们将上面得到的梯度离散化公式带进来,得到
激动人心的部分要来了!赶快会议一下各种三角公式!
让和分别表示顶点和的三角形内角。由于有
并且有
于是就可以得到
因此在整个局部平均区域上积分的时候会得到
,与,的位置关系在上图有给出。
于是,在顶点处,函数的拉普拉斯算子的离散平均为
这就是在计算机图形学中大名鼎鼎的余切公式了。
矩阵化求解
如果要求解肯定还是要具体写成矩阵形式的线性方程,接下来就介绍如何矩阵化一个拉普拉斯或者泊松方程。
矩阵化
考虑在三角mesh上的泊松方程或者更高阶偏微分方程的离散化及求解。标量值函数是通过在mesh顶点处的函数值的逐片线性内插定义的。从上面的推导我们知道了拉普拉斯可以写成线性求和的形式
如果使用余切离散化那么就是,。将线性和写成矩阵形式之后,我们有
其中,是对称矩阵
更高阶的拉普拉斯可以通过递归的方法得到
那么这个矩阵表示就很简单的对应拉普拉斯矩阵的k次幂。
因此在个顶点的mesh上更高阶的偏微分方程离散化之后会得到一个的线性系统
其中,且
矩阵性质
你以为上面就结束了吗?还没有呢!为了保证二次型的对称正定,还需要对上面推导出来的内容进一步调整。
稀疏性 简单说一下吧。拉普拉斯矩阵中只有对角元和边对应的元素是非的,其余全是0。根据欧拉公式,平均每一行大约7个非元素。
对称性 由于对角矩阵捣乱,所以矩阵不是对称的。不过对于任意阶的拉普拉斯系统很容易转换为对称系统,即
这个对称性应该很容易验证了。
正定性 一般来讲,解偏微分方程都需要边界条件。即对于一个线性系统,有部分变量保持不变,此时它们不再是未知量了。此时将对应的列移到右手边,即,同时对应的行从整个系统中移除。注意到此时整个系统还是保持对称的!!!在移除边界条件之后,可以证明矩阵是负定的!(简单点理解,有些行中对角元的绝对值大于该行其它列的元素绝对值的和。请注意,这只是直观理解,绝不是严格证明!!!)负定很简单,直接在每个上乘一个就行,因此我们最后得到
由此我们就得到了一个稀疏、对称且正定的线性系统。
参考文献
- M. Botsch, Ed., Polygon mesh processing. Natick, Mass: A K Peters, 2010.