翻译自 DISCRETE DIFFERENTIAL GEOMETRY: AN APPLIED INTRODUCTION 第六章 The Laplacian。如果有翻译错误或者不当的地方希望能指出,谢谢~
早先我们提到Laplace-Beltrami算子(通常就简写为拉普拉斯)在很多几何和物理等式中都扮演了基本角色。在这一章中我们将拉普拉斯用在针对三角曲面泊松方程的离散版本中。当这章讨论顶点法线时,我们将看到从两个看待问题的不同方式得到的对于拉普拉斯同样的离散表达式(通过余切函数):使用测试函数(test functions)(或者通常被称为Galerkin projection),或者通过对微分形式进行积分(通常被成为离散外微积分)。
基本性质
在我们开始讨论离散化之前,让我们先建立一些拉普拉斯算子和标准泊松问题
的事实。泊松方程展现了这个内容上所有的东西——比如,在物理中可能表示质量密度,这种情况下得到的解(在合适的常数条件下)给出了对应的重力位势。类似的,如果描述了电荷密度那么则给出对应的电势。在几何处理中非常多的事情可以通过求解一个泊松方程解决(比如,平滑一个曲面、计算带有指定奇点的向量场、甚至计算曲面上的测地距离)。
通常我们的兴趣在于求解没有边界的密实曲面上的泊松方程。
练习 一个二次可微函数被称为是调和的(harmonic),当它满足拉普拉斯的核,即。讨论只有在没有边界的密实连通域上的调和函数是常数函数。
你的讨论不必特别正式——有一对简单的刻画了这个主要思想的观测。这个事实是十分重要的因为它暗示了我们可以将一个常数加到泊松方程的任意解上。换句话说,如果满足,那么也一样因为。
练习 一个独立的事实是在没有边界的密实连通域上,常数函数不是的像。换句话说,不存在函数使得。为什么?
这个事实也很重要,因为它告诉我们何时给定的泊松方程可以求解。特别的,当有一个常数部分时那么该问题不是适定的(well-posed)。然而,在一些情况下,简单地移除常数部分可能就能说得通了。即,不需要尝试去求解,而是去求解,其中并且是的全部体积。然而,你必须保证这个技巧在你问题的上下文中是说得通的!
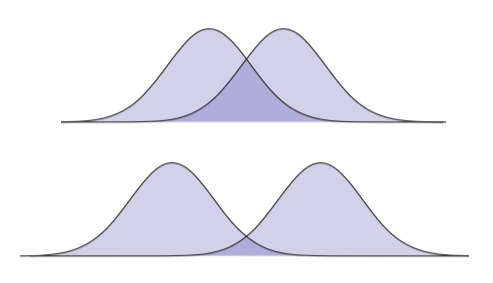
当使用像泊松方程这样的偏微分方程时,在函数之间进行内积通常是有用的。一个尤其通用的内积是内积,它是在全部的域上两个函数逐点乘积的积分:
直观上,这个操作类似于上一般的点乘:它测量对于两个函数“一致”的度。比如,上面两个函数有一个大的内积;下面两个有一个更小的内积(由深蓝色区域指示):
类似的,对于两个向量场和我们可以定义一个内积:
它测量了两个场在每个点处有多“一致”。
使用内积我们可以解释一个被称为格林第一等式(Green’s first identity)的重要关系。格林等式说的是对于任意满足要求的可微函数和:
其中表示在边界上的内积并且是向外的法线。
关于拉普拉斯的最后一个关键事实是它是半正定的,即满足对于所有的函数都有
(顺便,为什么这个值不是严格大于0的呢?)语言无法解释半正定的重要性。让我们考虑一个非常简单的例子:在平面中形式为的函数。任意一个这样的函数可以写为矩阵形式:
并且我们可以同样的定义是半正定的。但是它看起来是什么样子?就像下面描绘的,正定矩阵()看起来像一个碗,半正定矩阵()看起来像半圆柱,不定矩阵(取决于的值可正可负)看起来像马鞍:
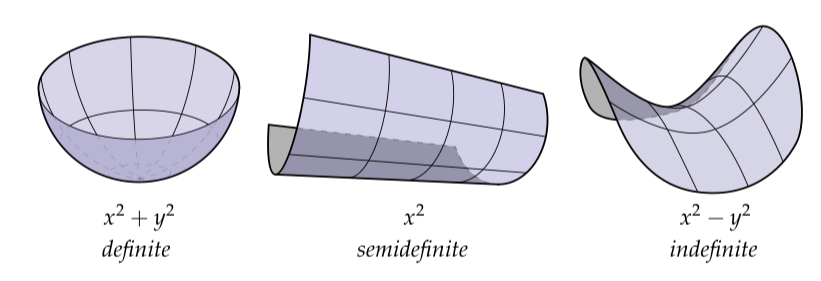
现在假设你是一个滑雪者,正在令人哀嚎的暴风雪中心地带。你非常冷而且精疲力尽,并且你知道你将你的卡车停在了一个平坦的区域,但是它到底在哪里呢?暴风雪刮的特别猛烈并且可见度很低——所以你能做的就是保持你的手指交叉并且沿着山的坡度下降。(相信我:当一个人在进行数值优化的时候他就是这么觉得的!)如果你是聪明的并且在Pos Def Valley滑雪那么你可以就保持向下并且很快就会安全回到卡车。但是可能你会在那天觉得更有一点冒险精神并且去了一趟Semi Def Valley。在这个情况下你仍然将达到底部,但是在找到你的车前可能必须返回高处并且沿着山谷的长度前进。最后,如果你的座右铭是“安全第二”那么你丢下了对暴风雪的小心并且在Indef Valley中驰骋。这种情况下你可能永远也回不去了!
简单点说:半正定矩阵是很好的因为找到它们描述的二次函数的最小值是很容易的——在数值线性代数中有非常多的工具是基于这个思想。对于像拉普拉斯,通常可以被看作无穷维矩阵的一类(如果你花一点时间去读下谱定理相关的内容,你会发现这个类比更深的内容),这样的半正定线性算子来讲也是同样。对于几何和物理中通常给定的泊松方程,是半正定的可真**是个好东西!
通过有限元方法离散化
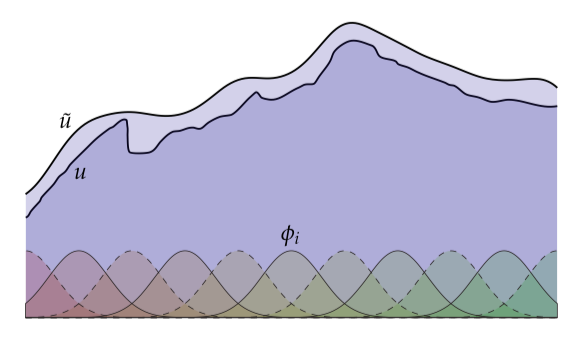
一个几何或者物理问题的解通常通过一个函数来描述:地球上每一点的温度,曲面上每一点的曲率,击中在你视网膜上每一点的光亮,等等。所以可能函数组成的空间十分惊人的大——过于大以至于不能在计算机上表示。有限元方法(finite element method (FEM))背后的思想是选取一个更小的函数空间并且并且尝试从这个空间中找到最有可能的解。更特别地,如果是一个问题真正的解并且是基函数(basis functions)的集合,那么我们可以寻找这些方程的线性组合
使得差值对于一些范数来讲足够小。(在上面我们看到一个具体的曲线和通过隆起状的基函数得到的最好的近似。)
让我们从一个非常简单的问题开始:假设我们有一个向量,并且想在两个基向量张成的平面上找到最好的近似:
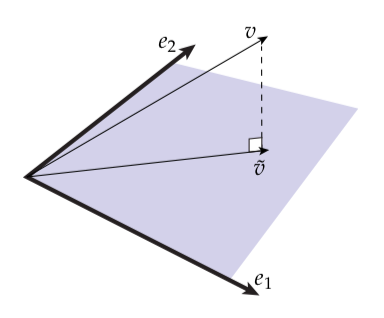
由于肯定在平面上,我们能做好的最好的情况是保证误差仅仅在法线方向上。换句话说,我们希望误差和两个基向量和正交:
在这个情况下我们得到了对于两个未知数的由两个线性方程组成的系统,并且可以很容易地计算最优向量。
现在有了一个更难的问题:假设我们想要解一个标准泊松问题
我们如何验证给定的函数是否是最可能的解?基本的思路仍然适用,只不过我们现在的基是函数而不是有限向量,并且简单的向量点乘由内积替换。不幸的是,当尝试求解泊松方程的时候我们不知道正确的解长什么样(在其它情况下我们早就知道!)所以不是误差,我们将必须看着残差,它测量了有多满足原始的方程。特别的,我们想“测试”残差沿着每个基方向消失:
再一次得到了一个线性方程系统。这个条件保证了解在大量可能的“测量”集合上表现得像真正的解。
接下来,让我们得到对于一个三角曲面的系统细节。基函数最自然的选择是逐片线性帽函数(hat functions),它在和它相关的顶点处为1并且在其它所有顶点处为0:
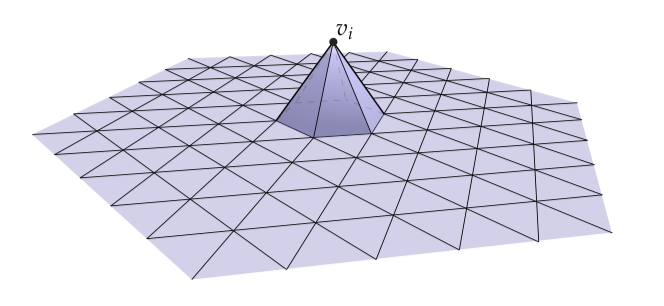
此时你可能会反对:如果所有的函数都是线性的,并且是一个二阶导数,每一次我们估计的时候不都会得到0吗?幸运的是我们被格林公式拯救了——让我们看看当我们将等式应用到我们的三角网格上的时候会发生什么,通过将积分分解为独立三角形上的求和:
如果这个网格没有边界那么最后的和会消失,因为相邻三角形的法线是相对的方向。因此沿着共享边的边界积分互相抵消了:
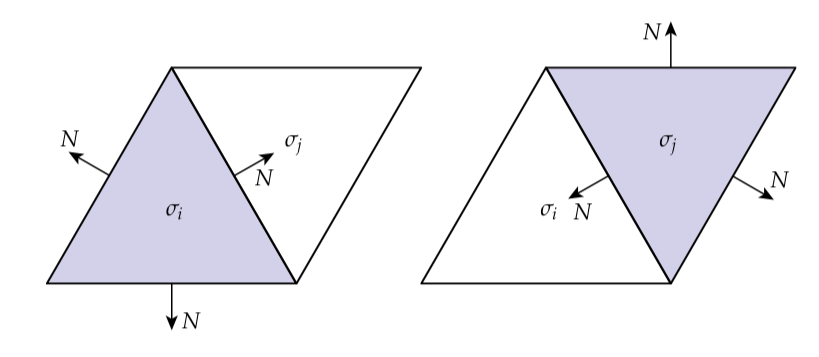
这种情况下,在每一个三角形中我们会剩下简单的
换句话说,我们可以“测试”只要我们可以计算待定解和每一个基函数的梯度。但是记住本身是这些基的线性结合,所以我们有
现在关键的事情变成了在每个三角形中两个基函数梯度之间的内积。如果我们可以计算这些,那么我们可以简单地构造矩阵
并且求解对于系数的问题
其中右手边的元素被给定为(即我们仅仅在右手边使用同样的“测量”)。
将所以的事实放在一起(有几个练习没有翻译),我们发现我们可以通过著名的余切公式表示顶点处的拉普拉斯
其中我们在顶点的邻域求和。
通过离散外微积分方法离散化
FEM的方式显示了一种相当标准的做法去离散化偏微分方程。但是让我们尝试一个不同的方法,基于离散外微积分(DEC)。相当有趣的是,虽然这两个方式十分不同,但是我们最后会得到一样的结果!
再一次我们想要求解泊松方程,(如果你记得我们对于微分算子的讨论)它也可以被表示为
我们早就在笔记中概括了如何使用离散外微积分离散化这类表达式,但是让我们一步步来。我们开始于一个0-型,它表示每个顶点处的一个数:
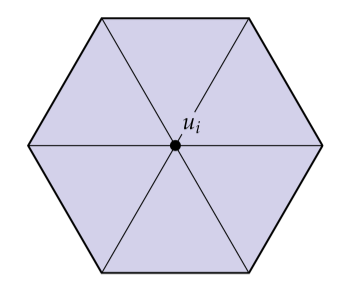
接着,我们计算离散外导数,它仅仅表示我们想要沿着每一条边积分这个导数:
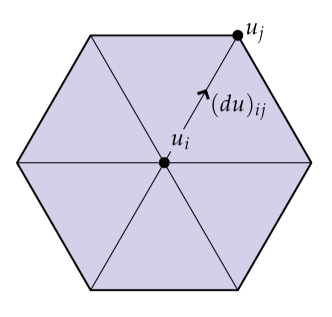
(注意到边的边界就是两个端点和。)Hodge星将沿着边的环流转变为穿过对应对偶边的通量。特别的,我们拿着沿着原始边的全部环流,将它除以边的长度得到平均逐点环流(average pointwise circulation),然后乘上对偶边的长度得到通过对偶边的全部通量:
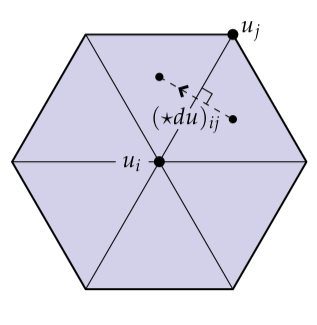
其中和分别为原始的和对偶边的长度。接下来,我们取的导数和在整个对偶胞腔上的积分:
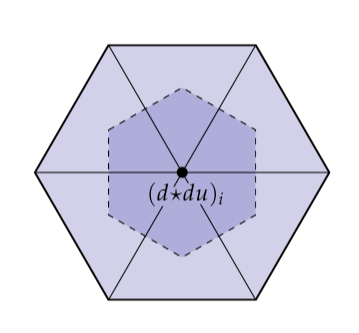
最后的Hodge星简单地将这个量除以的面积得到这个胞腔上的平均值,并且我们最后得到一个线性方程系统
其中是在顶点处右边的值。(对称矩阵通常更容易进行数值处理并且可以推导出更有效的算法。)另外一个看待这个变换的方式是想象我们离散化这个系统
换句话说,我们将0-型项的等式转变为n-型项的等式。当在曲面上操作的时候,算子有时被作为共形拉普拉斯(conformal Laplacian),因为当我们对曲面进行共形变换的时候它不会改变。或者说,我们可以将就看作是一个给我们在网格上每一个对偶胞腔上积分的拉普拉斯值(而不是逐点的值)的算子。
网格和矩阵
目前我们已经给出了一类像拉普拉斯算子的“算法的”描述。比如,我们确定在顶点处的标量函数的拉普拉斯可以约等于
其中和是在的邻域上获得的。在代码中,求和可以简单的写为循环并且在任意一个顶点处估计。然而,使用离散微分算子的一个关键部分是建立它们的矩阵表示。将算子编码成矩阵的动机是我们可以使用标准的数值线性代数包求解像
的系统。(为了让事情更麻烦,一些线性求解器非常喜欢使用被成为回调函数的算子的算法表示——然而,实际上我们就是需要矩阵。)
在泊松方程的情况中,我们想要对于任意一个顶点处值的向量构造矩阵(其中是网格上顶点的数量),表达式有效的估算上面的公式。但是让我们从一些更简单的事情开始——考虑一个算子,它计算所有邻域值的和:
我们如何构造一个矩阵表示这个算子呢?将考虑为一个机器,它在每一个顶点处取输入向量并且将另一个向量作为输出。为了让这个道路说得通,我们需要知道哪个值对应哪个顶点。换句话说,我们需要给我们网格的每个顶点分配一个独立的索引,在范围中:
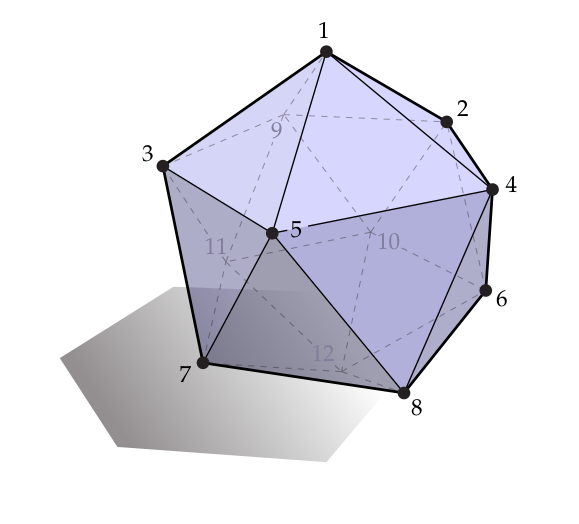
我们给哪个顶点具体分配哪个数字并不是很重要,只要没个顶点都有一个数字并且每个数字都有一个顶点就可以了。这个网格有12个顶点并且顶点1和顶点2,3,4,5,9相邻。因此我们可以计算邻域值的和为
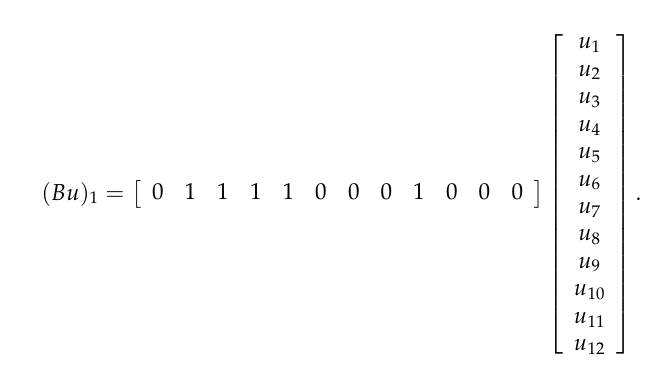
这里无论何时顶点是顶点1邻域的时候我们都将“1”放在第个位置上,其它的位置放0。因此这行给出了第一个顶点处的“输出”值,我们将它作为矩阵的第一行。这个矩阵的元素看起来像这样:

(你可以验证这个矩阵是对的,或者你可以出去晒晒太阳,这是你的选择。)实际上,幸运的是,我们不必“手动“构建矩阵——我们可以简单的开始于0矩阵然后通过循环我们网格的局部邻域去使用非0元素填充它。
最后,一个重要的需要注意的事情是中很多元素都是0。实际上,对于大多数离散算子0元素的数量远远超过非0元素的数量。因为这个原因,使用稀疏矩阵通常是个好主意,即仅仅储存非0元素位置和值的数据结构(而不是明确的储存矩阵中每一个独立元素)。稀疏矩阵数据结构的设计是一个非常有趣的问题,但是概念上你可以想象稀疏矩阵就是一个元组的列表,其中表示非0元素行和列的索引并且给出了它的值。